用图数据库建立问答应用
在本指南中,我们将介绍通过图形数据库创建问答链的基本方法。这些系统将允许我们询问有关图形数据库中的数据的问题并得到自然语言答案。
安全说明
构建图数据库的问答系统需要执行模型生成的图查询。这样做存在内在的风险。在满足您的链/智能体的需求下,确保您的数据库连接权限的范围始终尽可能缩小。这将减轻但不能消除构建模型驱动系统的风险。有关一般安全最佳实践的更多信息,请参阅 此处。
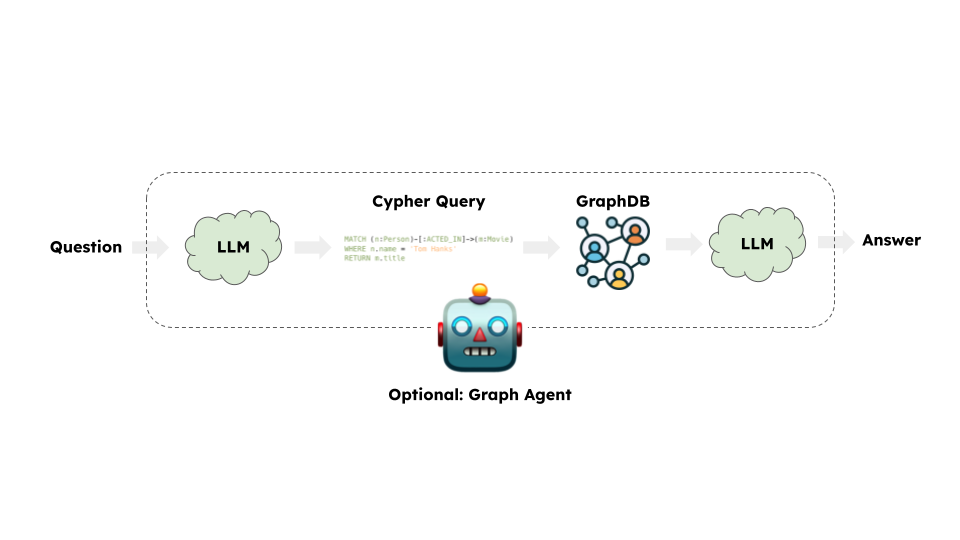
体系架构
从高层次来看,大多数图链的步骤是:
- 将问题转换为图数据库查询:模型将用户输入转换为图数据库查询(例如 Cypher)。
- 执行图数据库查询:执行图数据库查询。
- 回答问题:模型使用查询结果响应用户输入。
设置
首先,获取所需的包并设置环境��变量。在此示例中,我们将使用 Neo4j 图形数据库。
pip install --upgrade --quiet langchain langchain-community langchain-openai neo4j
在本指南中我们默认使用 OpenAI 模型。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
# Uncomment the below to use LangSmith. Not required.
# os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
# os.environ["LANGCHAIN_TRACING_V2"] = "true"
接下来,我们需要定义 Neo4j 凭证。按照以下 安装步骤 设置 Neo4j 数据库。
os.environ["NEO4J_URI"] = "bolt://localhost:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "password"
下面的示例将创建与 Neo4j 数据库的连接,并使用有关电影及其演员的示例数据填充该数据库。
from langchain_community.graphs import Neo4jGraph
graph = Neo4jGraph()
# Import movie information
movies_query = """
LOAD CSV WITH HEADERS FROM
'https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/movies/movies_small.csv'
AS row
MERGE (m:Movie {id:row.movieId})
SET m.released = date(row.released),
m.title = row.title,
m.imdbRating = toFloat(row.imdbRating)
FOREACH (director in split(row.director, '|') |
MERGE (p:Person {name:trim(director)})
MERGE (p)-[:DIRECTED]->(m))
FOREACH (actor in split(row.actors, '|') |
MERGE (p:Person {name:trim(actor)})
MERGE (p)-[:ACTED_IN]->(m))
FOREACH (genre in split(row.genres, '|') |
MERGE (g:Genre {name:trim(genre)})
MERGE (m)-[:IN_GENRE]->(g))
"""
graph.query(movies_query)
API 参考: Neo4jGraph
图模式
为了让 LLM 能够生成 Cypher 语句,它需要有关图模式的信息。当您实例化图形对象�时,它会检索有关图形模式的信息。如果稍后对图表进行任何更改,则可以运行refresh_schema方法来刷新架构信息。
graph.refresh_schema()
print(graph.schema)
Node properties are the following:
Movie {imdbRating: FLOAT, id: STRING, released: DATE, title: STRING},Person {name: STRING},Genre {name: STRING},Chunk {id: STRING, question: STRING, query: STRING, text: STRING, embedding: LIST}
Relationship properties are the following:
The relationships are the following:
(:Movie)-[:IN_GENRE]->(:Genre),(:Person)-[:DIRECTED]->(:Movie),(:Person)-[:ACTED_IN]->(:Movie)
太棒了!我们有一个可以查询的图形数据库。现在让我们尝试将其与LLM联系起来。
链
让我们使用一个简单的链,�它接受一个问题,将其转换为 Cypher 查询,执行查询,并使用结果来回答原始问题。
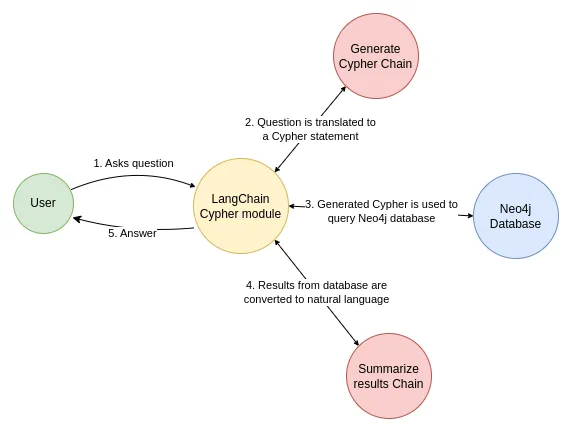
LangChain 为该工作流程提供了一个内置链,旨在与 Neo4j 配合使用:GraphCypherQAChain
from langchain.chains import GraphCypherQAChain
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}
验证关系方向
LLM可能会在生成的 Cypher 语句中的关系方向上遇到困难。由于图模式是预定义的,因此我们可以使用 validate_cypher 参数来验证并可选地更正生成的 Cypher 语句中的关系方向。
chain = GraphCypherQAChain.from_llm(
graph=graph, llm=llm, verbose=True, validate_cypher=True
)
response = chain.invoke({"query": "What was the cast of the Casino?"})
response
[1m> Entering new GraphCypherQAChain chain...[0m
Generated Cypher:
[32;1m[1;3mMATCH (:Movie {title: "Casino"})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name[0m
Full Context:
[32;1m[1;3m[{'actor.name': 'Joe Pesci'}, {'actor.name': 'Robert De Niro'}, {'actor.name': 'Sharon Stone'}, {'actor.name': 'James Woods'}][0m
[1m> Finished chain.[0m
{'query': 'What was the cast of the Casino?',
'result': 'The cast of Casino included Joe Pesci, Robert De Niro, Sharon Stone, and James Woods.'}